人工智��能 - RAG(检索增强生成)
大概半年前,我和同事讨论了一个AI应用问题:
如何实现使用自然语言搜索文件名称和内容?
例如以下两个情景:
- 搜索昨天新上传的图片文件。
- 搜索文件内容中包括
发票和爱米云有限公司的pdf文件。
使用传统的基于条件搜索的人机交互方式,需要在软件界面中选择多个条件才能完成上述搜索,这对普通用户而言有一些学习成本和操作复杂度。
我们希望直接在软件中使用自然语言搜索文件,也就是在搜索框中直接输入上述的 昨天新上传的图片文件 这段文字,就可以完成对应的搜索任务,类似下图的效果: 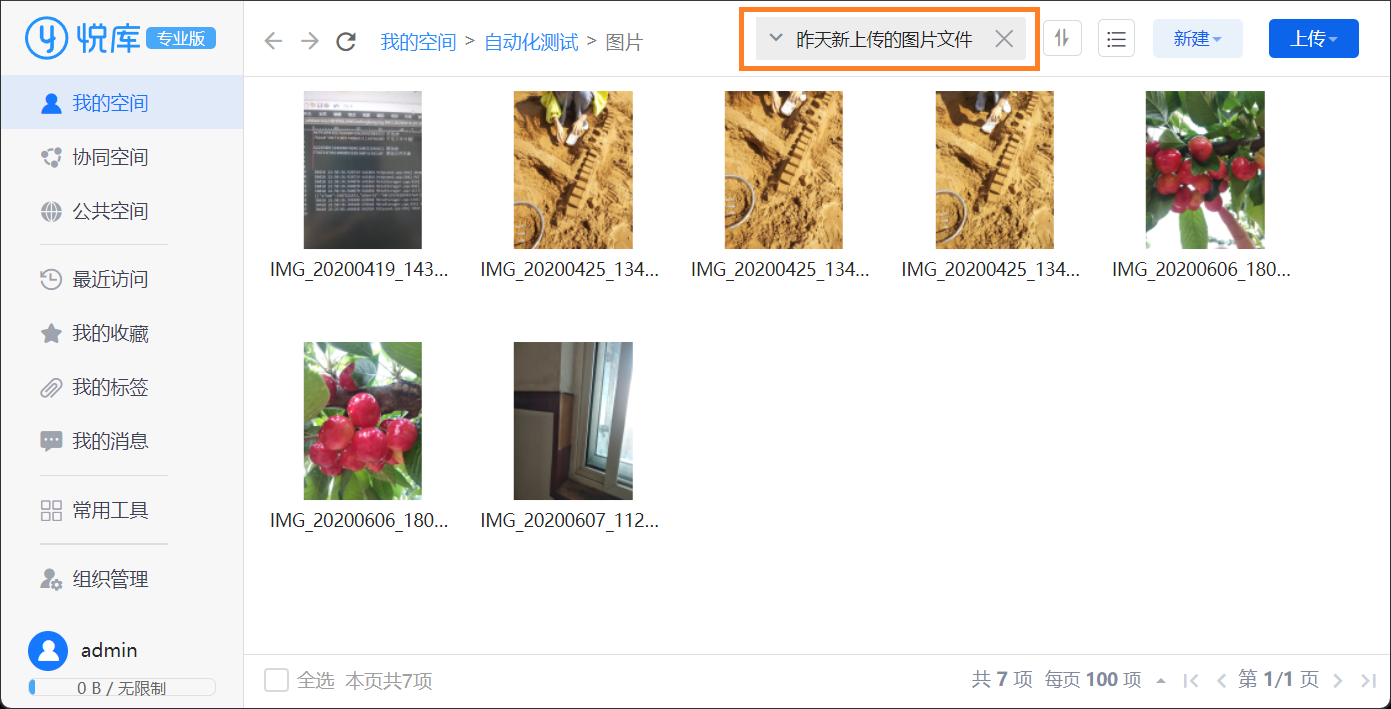
我们花时间做了一些调研,结果并不理想,主要有两个问题难以解决:一个问题是文件内容可能是动态变化的,而目前的主流LLM(大语言模型)都是通过静态数据训练的,显然不可�能每天用新数据训练一次LLM,那成本太高了。另外一个问题是由于文件有安全访问控制,因此每个人能访问的文件集不一样,显然不可能为每个人单独训练一个LLM,那成本太高了。最后我们得出的结论:能实现,但使用成本太高了,暂时搁置。
可是,峰回路转,柳暗花明,在一次偶然的机会,在elastic的博客上看到一篇技术文章,读后,我如获至宝。这种新技术被称为 检索增强生成(Retrieval-Augmented Generation,RAG)模型,原始论文在2020年的神经信息处理系统大会(NeurIPS 2020)上发表,论文的多名作者分别来自 Meta AI、伦敦大学学院和纽约大学。RAG模型从根本上解决了LLM不能与外部实时数据交互问题。
什么是检索增强生成(RAG)
**检索增强生成(RAG)**是一种使用外部来源检索信息,为大型语言模型 (LLM) 提供最新最准确的信息的技术。
概念有一些过于理论化,为了更形象的理解这一AI领域的最新技术,让我们以学生考试为例:
考试有闭卷和开卷两种方式,闭卷要求学生仅凭大脑记忆完成问题答案,而开卷学生则可以在使用大脑记忆的同时,借助课本、习题册等外部资料的内容完成问题答案。
在LLM模型中,AI作为学生相当于闭卷考试,只能根据过去已获取的知识(通过数据集训练)来回答问题,但在RAG系统中,AI作为学生则相当于开卷考试,它可以结合过去的知识和从外部来源中实时查询到的知识来回答问题,因此结果会更新更准确。
再举个非常简单的例子,您问LLM: 青岛今天会下雨吗?,在RAG技术出现之前它是无法给你答案的,因为它的训练数据集是过去的知识,并不知道今天发生了什么。但现在基于RAG技术,LLM可以通过互联网实时查询青岛今天的天气情况,然后反馈给你。
是的,本质上就是这么简单。
以下流程图概括了RAG的工作原理:
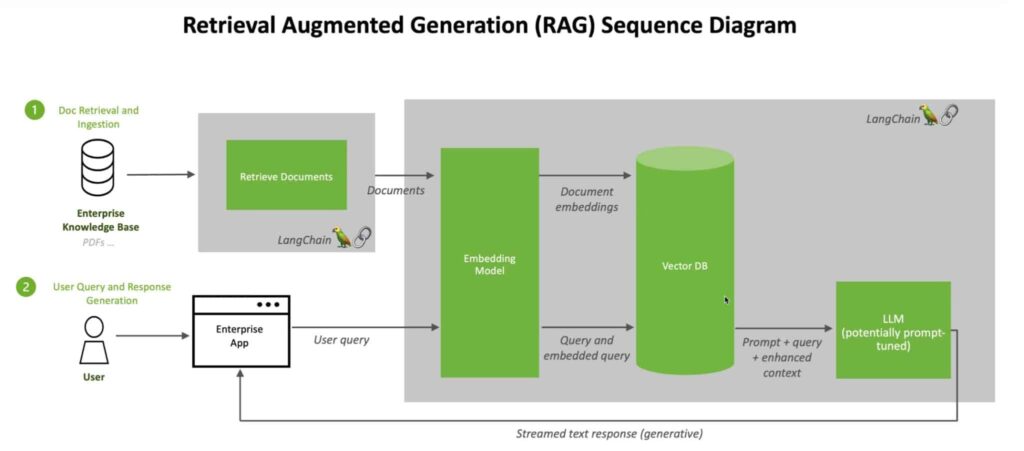
将 LLM 与嵌入模型和矢量数据库相结合(来源:Nvidia)
首先需要RAG模型需要从数据集中的文件中摄取文本或结构化内容,通过嵌入模型对其做降维处理后,即将高维的离散数据(如文本、文件元信息等)转换为低维的连续向量,然后加入到向量数据库中,等待后续LLM使用。
当您向 LLM 提问时,APP会将查询发送给嵌入模型,后者会将查询转换成向量条件以便在向量数据库中查询,查询的结果送到LLM, 形成最终的答案并提交给APP,最终反馈给您。
安全访问控制
假如您作为一名悦库企业网盘的用户,向LLM提出问题:搜索昨天新上传的图片文件
为了回答您的问题,LLM将先根据时间和图片类型条件搜索出所有文件,并进行权限过滤,因为向您展示的结果必须是您能有权访问的文件,然后将结果传递给 LLM,后者会生成简洁、个性化的答案。
因此,当LLM处理敏感数据时,从外部来源检索信息可能带来隐私问题,这可以使用向量数据库的文档级访问权限机制解决,以限制LLM对向量数据库的请求结果。
在更广泛的使用情景中,LLM不仅可以通过RAG访问外部文档类数据,还可以访问组织结构、人员信息、审计日志等更多的结构化信息,让AI模型具有更智能和个性化的交互能力。以下是IBM公司实现的内部AI的真实用例:
员工 Alice 了解到她儿子的学校今年余下时间的周三将提前放学。她想知道她是否可以以半天为单位休假,以及她是否有足够的假期来完成这一年。
为了制作回复,LLM 首先从 Alice 的人力资源文件中提取数据,以了解她作为长期员工可以享受多少假期,以及她一年还剩多少天。它还会搜索公司的政策,以验证她的假期是否可以休半天。这些事实被注入 Alice 的初始查询中,并传递给 LLM,后者会生成简洁、个性化的答案。
通过上面的用户实例,我们可以看出RAG在访问外部资源时,多数情况下都需要进行安全认证或权限检查,但由于RAG通常使用向量数据库检索数据(速度快,性能有保证),因此需要将外部源数据转换为向量数据,也需要将源数据的安全访问规则转换为向量数据库支持的安全规��则,并存储到向量数据库中供LLM后续检索使用。
未来
未来,随着各大公司对检索增强生成(RAG)的支持逐渐成熟化,RAG 将为LLM模型提供更多个性化、最新的数据,成为LLM与外部数据的桥梁。
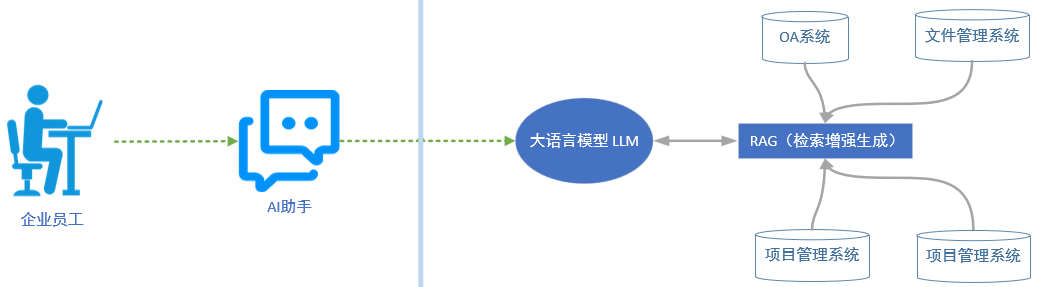
企业中的各种信息系统,例如OA、文件管理、项目管理等系统可以通过RAG连接到中心LLM模型上,这样企业提供一个AI助手,员工就可以通过自然语言与企业中所有信息系统交互,各个系统的数据可以使用AI统一分析和处理,为企业数据释放更大的价值。