悦库服务器-横向扩容
根据早先发表的文章《Linux部署重构方案》指导,我们在今年6月份完成施工并发布7.1版本,引入了分布式存储引擎,实现全数据热备,并且支持在线和离线方式全自动化部署包括扩展组件在内的整个悦库系统。
部分企业非常重视数据安全,已经不再满足于单台服务器内部的跨硬盘数据热备冗余,要求提供跨服务器的数据冗余能力。我们最近为多个客户实施了包含2台服务器的主从部署,这种部署方式可以实现其中一台服务器故障后,在另外一台服务器中数分钟内快速恢复服务和数据访问,而不需要考虑故障服务器的数据损失和迁移问题,从而有效抵御勒索病毒侵害以及服务器灾难性故障。
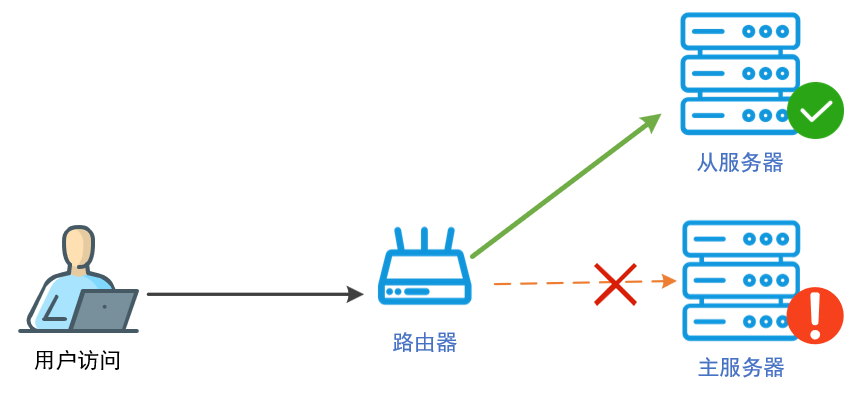
主从虽然不能像集群一样有服务器级的服务冗余能力,但拥有同等级别的数据冗余能力。集群部署需要至少3台服务器,而大部分企业都能够接受数分钟的服务故障时间,这样主从部��署就可以少用一台服务器,以体现成本优势了。
无论是主从还是集群部署,实现本身都有一定的复杂度,这涉及多个数据库服务、存储服务、WEB服务等的配置和协作,我们期望将这些技术问题自动化,让这种横向扩展部署更加简单方便。随着数据量和业务的增加,企业可以平滑的从1台服务器扩展到2台、3台甚至更多,以承载更大的文件存储量和访问量。
主从部署
主从部署由主服务器和从服务器共2台服务器组成,2台服务器部署的系统服务完全相同,仅是担任的角色不同,由主服务器承担所有服务的访问,从服务器作为备用服务器,对全数据进行热备,当主服务故障后,从服务器可以在数分钟内快速接管服务,不需要考虑主服务的数据损失和迁移问题。
主从部署主要考虑数据库和分布式存储两个核心服务的数据热备,以及从服务器的故障恢复问题。
数据库使用 主从配置方案,将主服务器配置为主数据库服务,将从服务器配置为从数据库服务,通过开启 binlog(Binary Log,二进制日志)和主从复制机制,实现数据的实时同步和热备份。
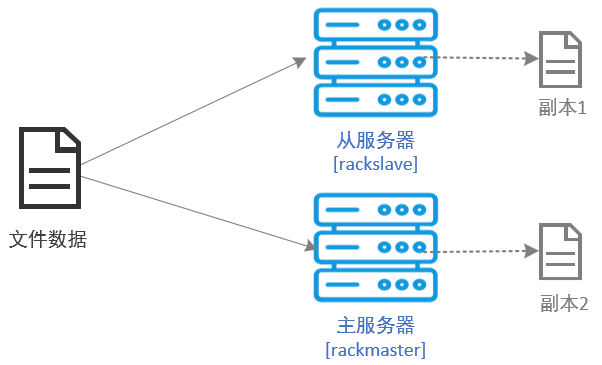
分布式存储使用 跨机架2份数据冗余 的配置方案,在主服务器部署主节点和卷节点并分别指向不同的物理存储盘并定义其机架名称为rackmaster,在从服务器只部署2个卷节点并定义其机架名称为rackslave。当上传下�载请求发生时,由主节点处理请求,然后根据配置策略将请求转发给对应的卷节点,而卷节点只负责数据的读写操作。以跨机架2份数据冗余 的配置方案为例,上传过程如下:
当主服务器发生故障时,整个系统服务将中断,这时需要运维人员确认主服务器故障并手动在从服务器中执行快速恢复服务的命令,从服务器不能像集群一样自动接管系统服务,因为2台服务器无法形成服务器集群,当其中主服务器因故障离线后,无法自动解决集群的脑裂问题。
脑裂(Split-Brain)是一种在分布式系统中发生的故障现象,当节点故障导致集群分裂成两个或多个独立的子系统时,每个子系统都认为自己是集群的唯一或主节点,从而在没有统一协调的情况下独立运行。
例如,在
主从部署的实例下,当主服务器和从服务器都运行正常,但它们之间的网络出现临时故障时,如果从服务器试图将自己提拔为主服务器角色,但此时实际上会出现两个主服务器,这就是“脑裂”问题,可能导致数据不一致和服务混乱。
在从服务器中执行快速恢复服务的过程,先将从数据库提升为主数据库,然后把分布式存储服务的2个卷节点中的1个提升为主节点,最后将从服务器IP修改为之前的主服务器IP。
集群部署
集群部署由3台及以上数量的服务器组成,具有服务器级冗余能力,当其中任意一台服务器故障后,整个服务依然可以正常运行。
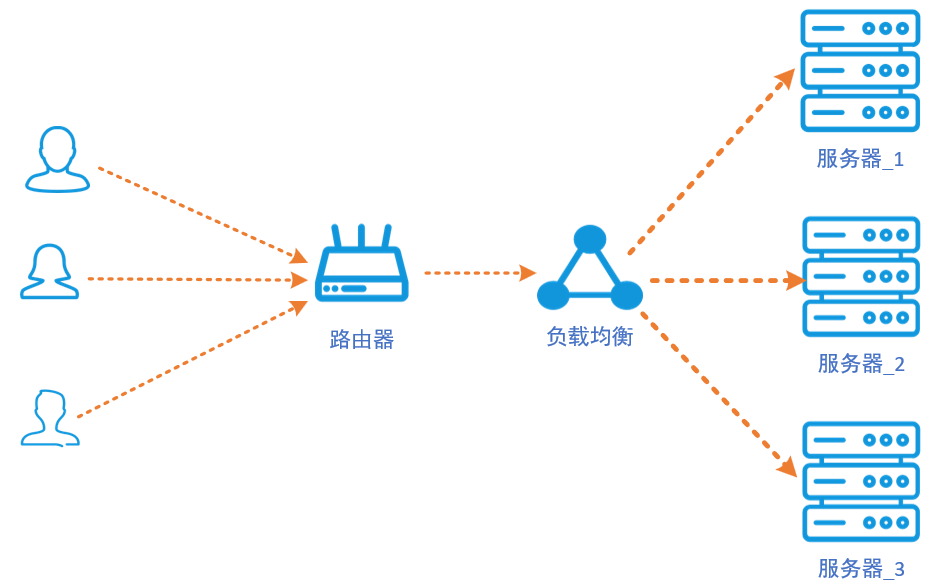
集群部署主要考虑数据库和分布式存储两个核心服务的集群化,并使用负载均衡分散单台服务器的访问压力。
数据库使用组复制配置方案,将多台服务器组成一个高可用的数据库集群。每台服务器都作为集群的一个节点,节点之间通过组复制协议进行数据同步。
分布式存储使用 跨机架2份数据冗余 的配置方案,在每台服务器上部署主节点和卷节点,分别指向不同的物理存储盘,然后为每台服务器定义其机架名称为rack_1、rack_2、rack_3...等。当上传下载请求发生时,由负载均衡处理请求,然后将请求分散转发给任意服务器上的存储服务中即可。当服务器数量为4台及以上时,可以开启纠删码存储方式,存储系统自动将一些长时间不访问的数据转换为纠删码存储,这样可以节省大约30%的存储空间,同时保持允许1台服务器故障的冗余能力。
集群部署根据服务器数量的不同,至少有1台服务器的故障冗余能力,任意一台服务器故障,整个服务的访问不受影响。
最后
在生产环境中,我们可以便捷地对现有服务器进行横向扩容,例如将现有的单机服务器部署提升为主从部署,或者将现有的主从部署提升为集群部署。